
线上问题排查常用命令
https://my.oschina.net/xiaolyuh/blog/4261951
内存瓶颈
free
free是查看内存使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
free -h -s 3表示每隔三秒输出一次内存情况,命令如下
[1014154@cc69dd4c5-4tdb5 ~]$ free
total used free shared buff/cache available
Mem: 119623656 43052220 45611364 4313760 30960072 70574408
Swap: 0 0 0
[1014154@cc69dd4c5-4tdb5 ~]$ free -h -s 3
total used free shared buff/cache available
Mem: 114G 41G 43G 4.1G 29G 67G
Swap: 0B 0B 0B
total used free shared buff/cache available
Mem: 114G 41G 43G 4.1G 29G 67G
Swap: 0B 0B 0BMem:是内存的使用情况。Swap:是交换空间的使用情况。total: 系统总的可用物理内存和交换空间大小。used: 已经被使用的物理内存和交换空间。free: 还有多少物理内存和交换空间可用使用,是真正尚未被使用的物理内存数量。shared:被共享使用的物理内存大小。buff/cache:被 buffer(缓冲区) 和 cache(缓存) 使用的物理内存大小。available: 还可以被应用程序使用的物理内存大小,它是从应用程序的角度看到的可用内存数量,available ≈ free + buffer + cache。
交换空间(swap space)
swap space 是磁盘上的一块区域,当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
vmstat(推荐)
vmstat(VirtualMeomoryStatistics,虚拟内存统计)是Linux中监控内存的常用工具,可对操作系统的虚拟内存、进程、CPU等的整体情况进行监视,推荐使用。
vmstat 5 3表示每隔5秒统计一次,一共统计三次。
procs
r:表示运行和等待CPU时间片的进程数(就是说多少个进程真的分配到CPU),这个值如果长期大于系统CPU个数,说明CPU不足,需要增加CPU。 b:表示在等待资源的进程数,比如正在等待I/O或者内存交换等。
memory
swpd:表示切换到内存交换区的内存大小,即虚拟内存已使用的大小(单位KB),如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。 free:表示当前空闲的物理内存。 buff:表示缓冲大小,一般对块设备的读写才需要缓冲 Cache:表示缓存大小,一般作为文件系统进行缓冲,频繁访问的文件都会被缓存,如果cache值非常大说明缓存文件比较多,如果此时io中的bi比较小,说明文件系统效率比较好。
swap
si:表示数据由磁盘读入内存;通俗的讲就是每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。 so:表示由内存写入磁盘,也就是由内存交换区进入内存的数据大小。
注意:一般情况下si、so的值都为0,如果si、so的值长期不为0,则说明系统内存不足,需要增加系统内存
io
bi:表示由块设备读入数据的总量,即读磁盘,单位kb/s bo:表示写到块设备数据的总量,即写磁盘,单位kb/s
注意:如果bi+bo的值过大,且wa值较大,则表示系统磁盘IO瓶颈。
system
in:表示某一时间间隔内观测到的每秒设备终端数。 cs:表示每秒产生的上下文切换次数,这个值要越小越好,太大了,要考虑调低线程或者进程的数目。例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
注意:这两个值越大,则由内核消耗的CPU就越多。
CPU
us:表示用户进程消耗的CPU时间百分比,us值越高,说明用户进程消耗CPU时间越多,如果长期大于50%,则需要考虑优化程序或者算法。 sy:表示系统内核进程消耗的CPU时间百分比,一般来说us+sy应该小于80%,如果大于80%,说明可能存在CPU瓶颈。 id:表示CPU处在空间状态的时间百分比。 wa:表示IP等待所占用的CPU时间百分比,wa值越高,说明I/O等待越严重,根据经验wa的参考值为20%,如果超过20%,说明I/O等待严重,引起I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者监控器的贷款瓶颈(主要是块操作)造成的。
sar
sar和free类似sar -r 3每隔三秒输出一次内存信息:
CPU瓶颈
查看机器cpu核数
查看CPU信息(型号)
查看物理CPU个数
查看每个物理CPU中core的个数(即核数)
查看逻辑CPU的个数
top
在Linux内核的操作系统中,进程是根据虚拟运行时间(由进程优先级、nice值加上实际占用的CPU时间进行动态计算得出)进行动态调度的。在执行进程时,需要从用户态转换到内核态,用户空间不能直接操作内核空间的函数。通常要利用系统调用来完成进程调度,而用户空间到内核空间的转换通常是通过软中断来完成的。例如要进行磁盘操作,用户态需要通过系统调用内核的磁盘操作指令,所以CPU消耗的时间被切分成用户态CPU消耗、系统(内核) CPU 消耗,以及磁盘操作 CPU 消耗。执行进程时,需要经过一系列的操作,进程首先在用户态执行,在执行过程中会进行进程优先级的调整(nice),通过系统调用到内核,再通过内核调用,硬中断、软中断,让硬件执行任务。执行完成之后,再从内核态返回给系统调用,最后系统调用将结果返回给用户态的进程。
top可以查看CPU总体消耗,包括分项消耗,如User,System,Idle,nice等。Shift + H显示java线程;Shift + M按照内存使用排序;Shift + P按照CPU使用时间(使用率)排序;Shift + T按照CPU累积使用时间排序;多核CPU,进入top视图1,可以看到各各CPU的负载情况。
第一行:15:24:11 up 8 days, 7:52, 1 user, load average: 5.73, 6.85, 7.33: 15:24:11 系统时间,up 8 days 运行时间,1 user 当前登录用户数,load average 负载均衡情况,分别表示1分钟,5分钟,15分钟负载情况。
第二行:Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie: 总进程数17,运行数1,休眠 16,停止0,僵尸进程0。
第三行:%Cpu(s): 13.9 us, 9.2 sy, 0.0 ni, 76.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.7 st: 用户空间CPU占比13.9%,内核空间CPU占比9.2%,改变过优先级的进程CPU占比0%,空闲CPU占比76.1,IO等待占用CPU占比0.1%,硬中断占用CPU占比0%,软中断占用CPU占比0.1%,当前VM中的cpu 时钟被虚拟化偷走的比例0.7%。
第四和第五行表示内存和swap区域的使用情况。
第七行表示:
PID: 进程idUSER:进程所有者PR:进程优先级NI:nice值。负值表示高优先级,正值表示低优先级VIRT:虚拟内存,进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES:常驻内存,进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR:共享内存,共享内存大小,单位kbS:进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU:上次更新到现在的CPU时间占用百分比%MEM:进程使用的物理内存百分比TIME+:进程使用的CPU时间总计,单位1/100秒COMMAND:进程名称(命令名/命令行)
计算在cpu load里面的uninterruptedsleep的任务数量
sar
通过sar -u 3可以查看CUP总体消耗占比:
%user:用户空间的CPU使用。%nice: 改变过优先级的进程的CPU使用率。%system: 内核空间的CPU使用率。%iowait: CPU等待IO的百分比 。%steal: 虚拟机的虚拟机CPU使用的CPU。%idle: 空闲的CPU。
在以上的显示当中,主要看%iowait和%idle:
若
%iowait的值过高,表示硬盘存在I/O瓶颈;若
%idle的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量;若
%idle的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU;
定位线上最耗CPU的线程
准备工作
启动一个程序。 arthas-demo是一个简单的程序,每隔一秒生成一个随机数,再执行质因数分解,并打印出分解结果。
通过top命令找到最耗时的进程
top命令找到最耗时的进程找到进程号是98344。
找到进程中最耗CUP的线程
使用ps -Lp #pid cu命令,查看某个进程中的线程CPU消耗排序:
看TIME列可以看出那个线程耗费CUP多,根据LWP列可以看到线程的ID号,但是需要转换成16进制才可以查询线程堆栈信息。
获取线程id的十六进制码
使用printf '%x\n' 98345命令做进制转换:
查看线程堆栈信息
使用jstack获取堆栈信息jstack 98344 | grep -A 10 18029:
通过命令我们可以看到这个线程的对应的耗时代码是在demo.MathGame.main(MathGame.java:17)
网络瓶颈
定位丢包,错包情况
watch more /proc/net/dev用于定位丢包,错包情况,以便看网络瓶颈,重点关注drop(包被丢弃)和网络包传送的总量,不要超过网络上限:
最左边的表示接口的名字,Receive表示收包,Transmit表示发送包;
bytes:表示收发的字节数;packets:表示收发正确的包量;errs:表示收发错误的包量;drop:表示收发丢弃的包量;
查看路由经过的地址
traceroute ip可以查看路由经过的地址,常用来统计网络在各个路由区段的耗时,如:
查看网络错误
netstat -i可以查看网络错误:
Iface: 网络接口名称;MTU: 最大传输单元,它限制了数据帧的最大长度,不同的网络类型都有一个上限值,如:以太网的MTU是1500;RX-OK:接收时,正确的数据包数。RX-ERR:接收时,产生错误的数据包数。RX-DRP:接收时,丢弃的数据包数。RX-OVR:接收时,由于过速(在数据传输中,由于接收设备不能接收按照发送速率传送来的数据而使数据丢失)而丢失的数据包数。TX-OK:发送时,正确的数据包数。TX-ERR:发送时,产生错误的数据包数。TX-DRP:发送时,丢弃的数据包数。TX-OVR:发送时,由于过速而丢失的数据包数。Flg:标志,B 已经设置了一个广播地址。L 该接口是一个回送设备。M 接收所有数据包(混乱模式)。N 避免跟踪。O 在该接口上,禁用ARP。P 这是一个点到点链接。R 接口正在运行。U 接口处于“活动”状态。
包的重传率
cat /proc/net/snmp用来查看和分析240秒内网络包量,流量,错包,丢包。通过RetransSegs和OutSegs来计算重传率tcpetr=RetransSegs/OutSegs。
重传率=292/223186≈0.13%
平均每秒新增TCP连接数:通过/proc/net/snmp文件得到最近240秒内PassiveOpens的增量,除以240得到每秒的平均增量;
机器的TCP连接数 :通过/proc/net/snmp文件的CurrEstab得到TCP连接数;
平均每秒的UDP接收数据报:通过/proc/net/snmp文件得到最近240秒内InDatagrams的增量,除以240得到平均每秒的UDP接收数据报;
平均每秒的UDP发送数据报:通过/proc/net/snmp文件得到最近240秒内OutDatagrams的增量,除以240得到平均每秒的UDP发送数据报;
磁盘瓶颈
查磁盘空间
查看磁盘剩余空间
查看磁盘剩余空间使用df -hl命令:
查看磁盘已使用空间
du -sh命令是查看磁盘已使用空间的情况,这里的“已使用的磁盘空间”意思是指定的文件下的整个文件层次结构所使用的空间,在没给定参数的情况下,du报告当前目录所使用的磁盘空间。其实就是显示文件或目录所占用的磁盘空间的情况:
-h:输出文件系统分区使用的情况,例如:10KB,10MB,10GB等。-s:显示文件或整个目录的大小,默认单位是KB。
du的详细信息可以通过man du查看。
查看磁盘读写情况
查看磁盘总体读写情况
通iostat查看磁盘总体的读写情况:
tps:该设备每秒的传输次数。kB_read/s:每秒从设备(drive expressed)读取的数据量;kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;kB_read: 读取的总数据量;kB_wrtn:写入的总数量数据量;
查看磁盘详细读写情况
通过iostat -x 1 3可以看到磁盘详细读写情况,没隔一秒输出一次一共输出3次,当看到I/O等待时间所占CPU时间的比重很高的时候,首先要检查的就是机器是否正在大量使用交换空间,同时关注iowait占比cpu的消耗是否很大,如果大说明磁盘存在大的瓶颈,同时关注await,表示磁盘的响应时间以便小于5ms:
avg-cpu表示总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值:
%user:CPU处在用户模式下的时间百分比。%nice:CPU处在带NICE值的用户模式下的时间百分比。%system:CPU处在系统模式下的时间百分比。%iowait:CPU等待输入输出完成时间的百分比,如果%iowait的值过高,表示硬盘存在I/O瓶颈。%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。%idle:CPU空闲时间百分比,如果%idle值高,表示CPU较空闲;如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量;如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。。
Device表示设备信息:
rrqm/s:每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并wrqm/s:每秒对该设备的写请求被合并次数r/s:每秒完成的读次数w/s:每秒完成的写次数rkB/s:每秒读数据量(kB为单位)wkB/s:每秒写数据量(kB为单位)avgrq-sz:平均每次IO操作的数据量(扇区数为单位)avgqu-sz:平均等待处理的IO请求队列长度await:平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)svctm:平均每次IO请求的处理时间(毫秒为单位)%util:一秒中有百分之多少的时间用于 I/O如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷。idle小于70% IO压力就较大了,一般读取速度有较多的wait。
iostat -xmd 1 3:新增m选项可以在输出是使用M为单位。
查看最耗IO的进程
一般先通过iostat查看是否存在io瓶颈,再使用iotop命令来定位那个进程最耗费IO:
通过iotop -p pid可以查看单个进程的IO情况:
应用瓶颈
查看某个进程的PID
如查看java的进程的pid,ps -ef | grep java:
查看特定进程的数量
如查看java进程的数量,ps -ef | grep java| wc -l:
查看线程是否存在死锁
查看线程是否存在死锁,jstack -l pid:
查看某个进程的线程数
ps -efL | grep [PID] | wc -l,如:
查看具体有哪些线程用ps -Lp [pid] cu:
统计所有的log文件中,包含Error字符的行
find / -type f -name "*.log" | xargs grep "ERROR",这个在排查问题过程中比较有用:
应用启动时指定JVM参数
java -jar -Xms128m -Xmx1024m -Xss512k -XX:PermSize=128m -XX:MaxPermSize=64m -XX:NewSize=64m -XX:MaxNewSize=256m arthas-demo.jar,如:
总结
在使用linux命令时,如果想看帮助可以使用--help或者man查看帮助信息:
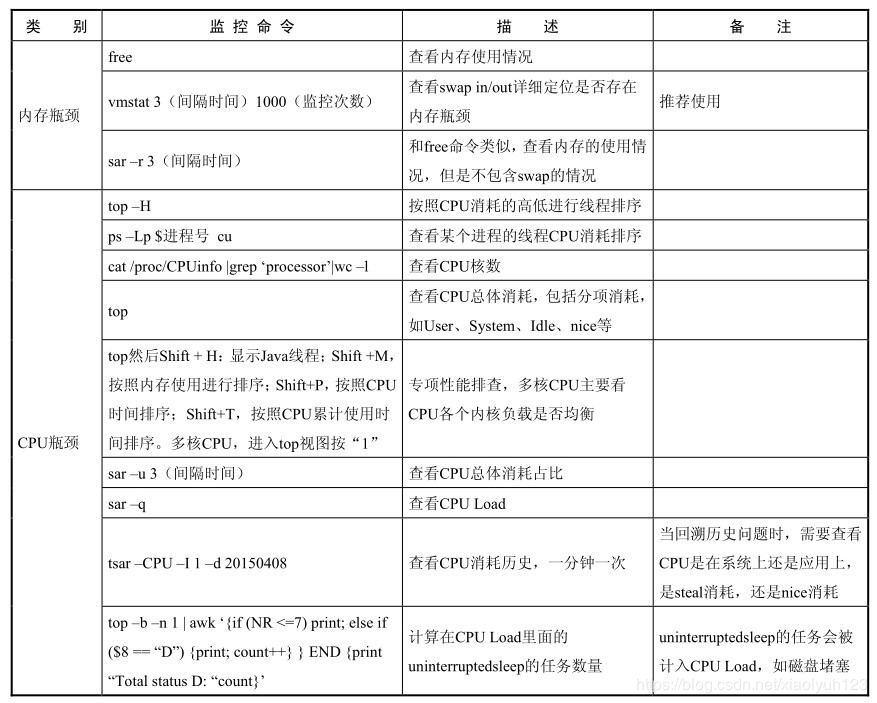
类别
监控命令
描述
备注
内存瓶颈
free
查看内存使用
vmstat 3(间隔时间) 100(监控次数)
查看swap in/out详细定位是否存在性能瓶颈
推荐使用
sar -r 3
和free命令类似,查看内存的使用情况,但是不包含swap的情况
cpu瓶颈
top -H
按照cpu消耗高低进行排序
ps -Lp 进程号 cu
查看某个进程的cpu消耗排序
cat /proc/cpuinfo |grep 'processor'|wc -l
查看cpu核数
top
查看cpu总体消耗,包括分项消耗如user,system,idle,nice等消耗
top 然后shift+h:显示java线程,然后shift+M:按照内存使用进行排序;shift+P:按照cpu时间排序;shift+T:按照cpu累计使用时间排序多核cpu,按“1”进入top视图
专项性能排查,多核CPU主要看CUP各个内核的负载情况
sar -u 3(间隔时间)
查看cpu总体消耗占比
sar -q
查看cpu load
top -b -n 1 | awk '{if (NR<=7)print;else if($8=="D"){print;count++}}END{print "Total status D:"count}'
计算在cpu load里面的uninterruptedsleep的任务数量 uninterruptedsleep的任务会被计入cpu load,如磁盘堵塞
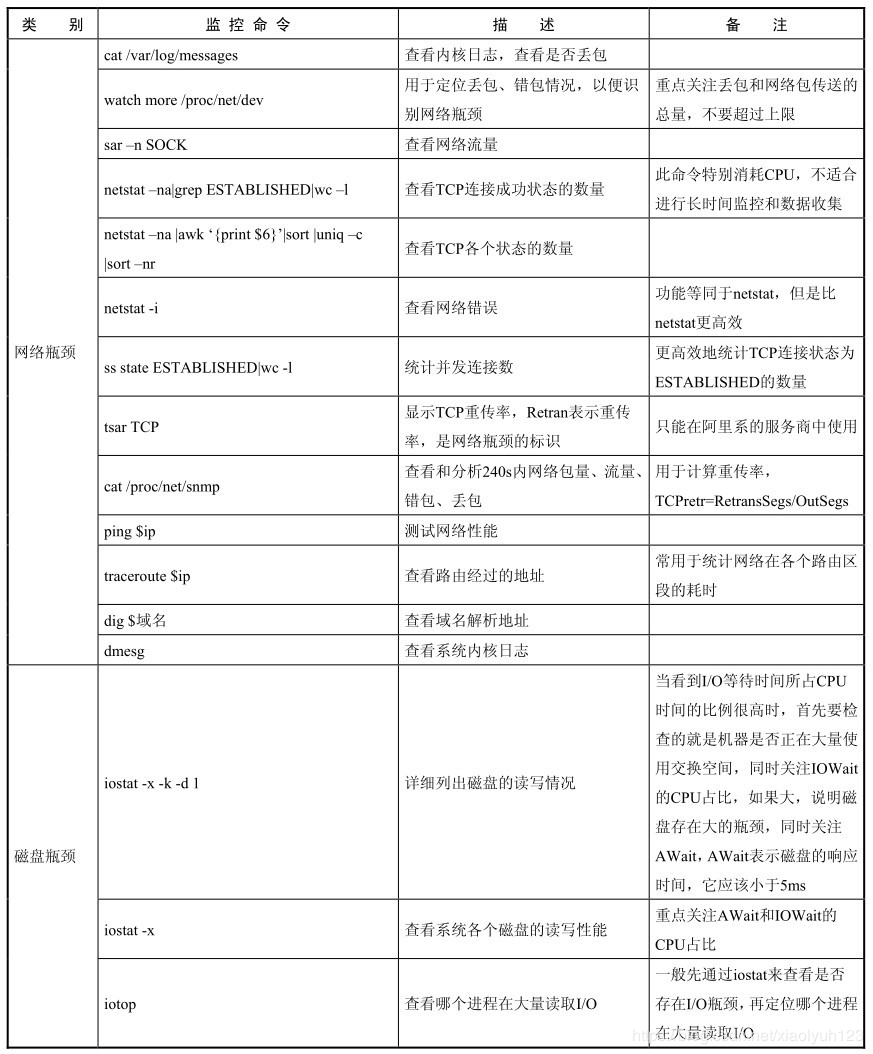
网络瓶颈
cat /var/log/messages
查看内核日志,查看是否丢包
watch more /proc/net/dev
用于定位丢包,错包情况,以便看网络瓶颈
重点关注drop(包被丢弃)和网络包传送的总量,不要超过网络上限
sar -n SOCK
查看网络流量
netstat -na|grep ESTABLISHED|wc -l
查看tcp连接成功状态的数量
此命令特别消耗cpu,不适合进行长时间监控数据收集
netstat -na|awk'{print $6}'|sort |uniq -c |sort -nr
看tcp各个状态数量
netstat -i
查看网络错误
ss state ESTABLISHED| wc -l
更高效地统计tcp连接状态为ESTABLISHED的数量
cat /proc/net/snmp
查看和分析240秒内网络包量,流量,错包,丢包
用于计算重传率tcpetr=RetransSegs/OutSegs
ping $ip
测试网络性能
traceroute $ip
查看路由经过的地址
常用于定位网络在各个路由区段的耗时
dig $域名
查看域名解析地址
dmesg
查看系统内核日志
磁盘瓶颈
iostat -x -k -d 1
详细列出磁盘的读写情况
当看到I/O等待时间所占CPU时间的比重很高的时候,首先要检查的就是机器是否正在大量使用交换空间,同时关注iowait占比cpu的消耗是否很大,如果大说明磁盘存在大的瓶颈,同时关注await,表示磁盘的响应时间以便小于5ms
iostat -x
查看系统各个磁盘的读写性能
重点关注await和iowait的cpu占比
iotop
查看哪个进程在大量读取IO
一般先通过iostat查看是否存在io瓶颈,再定位哪个进程在大量读取IO
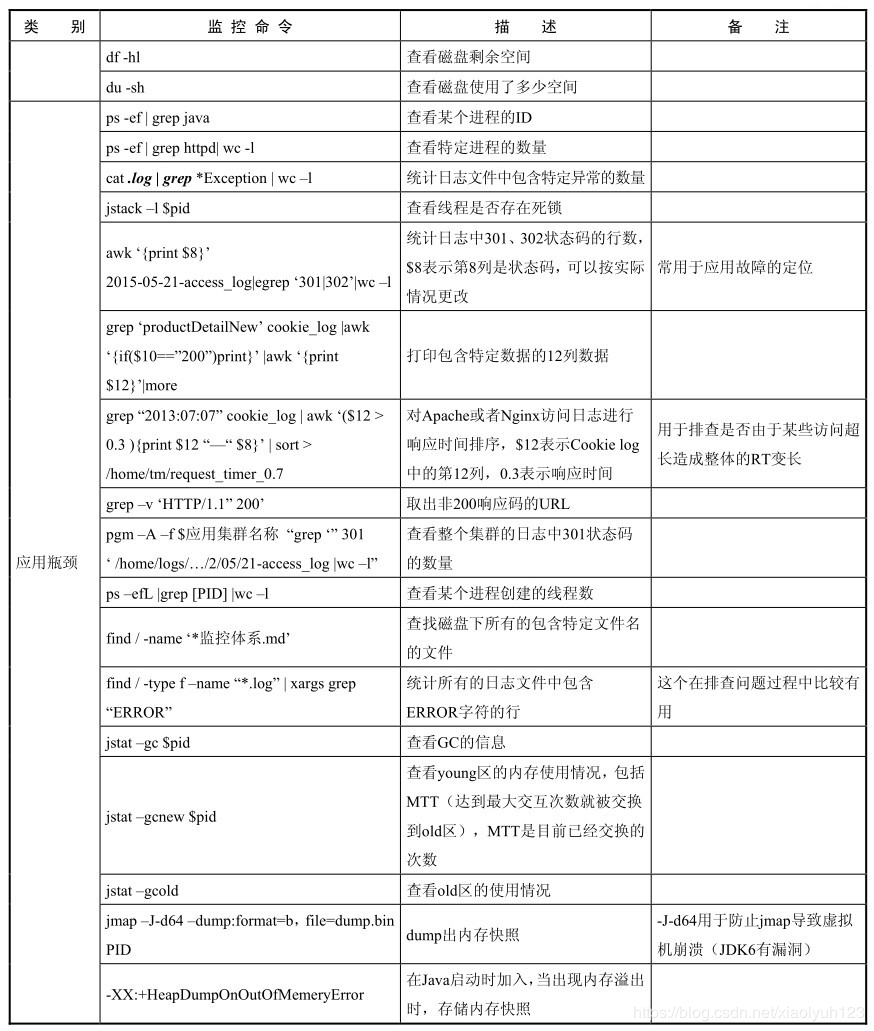
df -hl
查看磁盘剩余空间
du -sh
查看磁盘使用了多少空间
应用瓶颈
ps -ef
grep java
查看某个进程的id号
ps -ef | grep httpd| wc -l
查看特定进程的数量
cat .log | grep Exception| wc -l
统计日志文件中包含特定异常数量
jstack -l pid
用于查看线程是否存在死锁
awk'{print $8}' 2017-05-22-access_log|egrep '301|302'| wc -l
统计log中301、302状态码的行数,$8表示第八列是状态码,可以根据实际情况更改
常用于应用故障定位
grep 'wholesaleProductDetailNew' cookie_log | awk '{if($10=="200")}'print}'
awk 'print $12' | more
打印包含特定数据的12列数据
grep "2017:05:22" cookielog | awk '($12>0.3){print $12 "--" $8}' | sort > 目录地址
对apache或者nginx访问log进行响应时间排序,$12表示cookie log中的12列表示响应时间 用于排查是否是由于是某些访问超长造成整体的RT变长
grep -v 'HTTP/1.1" 200'
取出非200响应码的URL
pgm -A -f $应用集群名称 "grep "'301' log文件地址 | wc -l"
查看整个集群的log中301状态码的数量
ps -efL | grep [PID] | wc -l
查看某个进程创建的线程数
find / -type f -name "*.log" | xargs grep "ERROR"
统计所有的log文件中,包含Error字符的行
这个在排查问题过程中比较有用
jstat -gc [pid]
查看gc情况
jstat -gcnew [pid]
查看young区的内存使用情况,包括MTT(最大交互次数就被交换到old区),TT是目前已经交换的次数
jstat -gcold
查看old区的内存使用情况
jmap -J-d64 -dump:format=b,file=dump.bin PID
dump出内存快照
-J-d64防止jmap导致虚拟机crash(jdk6有bug)
-XX:+HeapDumpOnOutOfMemeryError
在java启动时加入,当出现内存溢出时,存储内存快照
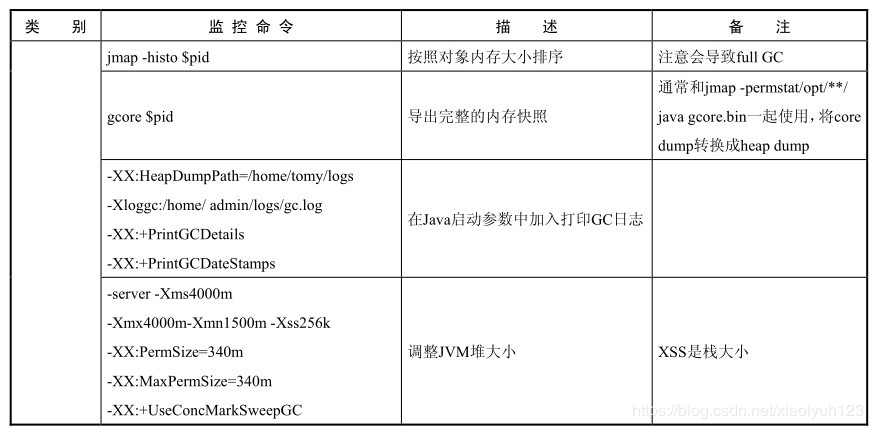
jmap -histo [pid]
按照对象内存大小排序
注意会导致full gc
gcore [pid]
导出完成的内存快照
通常和jmap -permstat /opt/**/java gcore.bin一起使用,将core dump转换成heap dump
-XX:HeapDumpPath=/home/logs -Xloggc:/home/log/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
在Java启动参数中加入,打印gc日志
-server -Xms4000m -Xmx4000m -Xmn1500m -Xss256k -XX:PermSize=340m -XX:MaxPermSize=340m -XX:+UseConcMarkSweepGC
调整JVM堆大小
xss是栈大小
Last updated